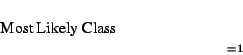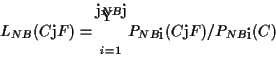In this section we describe all the algorithms presented in this paper as well as the signature-based method used for comparison. We used three different data mining algorithms to generate classifiers with different features: RIPPER, Naive Bayes, and a Multi-Classifier system.
We describe the signature-based method first.
We examine signature-based methods to compare our results to traditional anti-virus methods. Signature-based detection methods are the most commonly used algorithms in industry [27]. These signatures are picked to differentiate one malicious executable from another, and from benign programs. These signatures are generated by an expert in the field or an automatic method. Typically, a signature is picked to illustrate the distinct properties of a specific malicious executable.
We implemented a signature-based scanner with this method that follows a simple algorithm for signature generation. First, we calculated the byte-sequences that were only found in the malicious executable class. These byte-sequences were then concatenated together to make a unique signature for each malicious executable example. Thus, each malicious executable signature contained only byte-sequences found in the malicious executable class. To make the signature unique, the byte-sequences found in each example were concatenated together to form one signature. This was done because a byte-sequence that is only found in one class during training could possibly be found in the other class during testing [9], and lead to false positives in testing.
The method described above for the commercial scanner was never intended to detect unknown malicious binaries, but the data mining algorithms that follow were built to detect new malicious executables.
The next algorithm we used, RIPPER [3], is an inductive rule learner. This algorithm generated a detection model composed of resource rules that was built to detect future examples of malicious executables. This algorithm used libBFD information as features.
RIPPER is a rule-based learner that builds a set of rules that identify the classes while minimizing the amount of error. The error is defined by the number of training examples misclassified by the rules.
An inductive algorithm learns what a malicious executable is given a set of training examples. The four features seen in Table 2 are:
and finally the class question ``Is it malicious?''
The defining property of any inductive learner is that no a priori assumptions have been made regarding the final concept. The inductive learning algorithm makes as its primary assumption that the data trained over is similar in some way to the unseen data.
A hypothesis generated by an inductive learning algorithm for this learning problem has four attributes. Each attribute will have one of these values:
For example, the hypothesis
![]() and the
hypothesis
and the
hypothesis
![]() would make the first example true.
would make the first example true.
![]() would make any feature set true and
would make any feature set true and
![]() is the set of features for example one.
is the set of features for example one.
The algorithm we describe is Find-S [20]. Find-S finds the most specific hypothesis that is consistent with the training examples. For a positive training example the algorithm replaces any attribute in the hypothesis that is inconsistent with the training example with a more general attribute. Of all the hypotheses values 1 is more general than 2 and 2 is more general than 3. For a negative example the algorithm does nothing. Positive examples in this problem are defined to be the malicious executables and negative examples are the benign programs.
The initial hypothesis that Find-S starts with is
![]() .
This hypothesis is the most specific because it is true over
the fewest possible examples, none. Examining the first positive example in
Table 2,
.
This hypothesis is the most specific because it is true over
the fewest possible examples, none. Examining the first positive example in
Table 2,
![]() ,
the algorithm
chooses the next most specific hypothesis
,
the algorithm
chooses the next most specific hypothesis
![]() .
The next positive example,
.
The next positive example,
![]() ,
is inconsistent
with the hypothesis in its first and fourth attribute (``Does it have a GUI?''
and ``Does it delete files?'') and those attributes in the hypothesis get
replaced with the next most general attribute,
,
is inconsistent
with the hypothesis in its first and fourth attribute (``Does it have a GUI?''
and ``Does it delete files?'') and those attributes in the hypothesis get
replaced with the next most general attribute, ![]() .
.
The resulting hypothesis after two positive examples is
![]() .
The algorithm skips the third example, a negative
example, and finds that this hypothesis is consistent with the final example
in Table 2. The final rule for the training data listed
in Table 2 is
.
The algorithm skips the third example, a negative
example, and finds that this hypothesis is consistent with the final example
in Table 2. The final rule for the training data listed
in Table 2 is
![]() .
The
rule states that the attributes of a malicious executable, based on training
data, are that it has a malicious function and compromises system security.
This is consistent with the definition of a malicious executable we gave in
the introduction. It does not matter in this example if a malicious
executable deletes files, or if it has a GUI or not.
.
The
rule states that the attributes of a malicious executable, based on training
data, are that it has a malicious function and compromises system security.
This is consistent with the definition of a malicious executable we gave in
the introduction. It does not matter in this example if a malicious
executable deletes files, or if it has a GUI or not.
Find-S is a relatively simple algorithm while RIPPER is more complex. RIPPER looks at both positive and negative examples to generate a set of hypotheses that more closely approximate the target concept while Find-S generates one hypothesis that approximates the target concept.
The next classifier we describe is a Naive Bayes classifier [6]. The naive Bayes classifier computes the likelihood that a program is malicious given the features that are contained in the program. This method used both strings and byte-sequence data to compute a probability of a binary's maliciousness given its features.
Nigam et al. [21] performed a similar experiment when they classified text documents according to which newsgroup they originated from. In this method we treated each executable's features as a text document and classified based on that. The main assumption in this approach is that the binaries contain similar features such as signatures, machine instructions, etc.
Specifically, we wanted to compute the class of a program given that the program contains a set of features F. We define C to be a random variable over the set of classes: benign, and malicious executables. That is, we want to compute P(C|F), the probability that a program is in a certain class given the program contains the set of features F. We apply Bayes rule and express the probability as:
To use the naive Bayes rule we assume that the features occur independently from one another. If the features of a program F include the features F1,F2,F3,...,Fn, then equation (1) becomes:
Each P(Fi|C) is the frequency that string Fi occurs in a program of class C. P(C) is the proportion of the class C in the entire set of programs.
The output of the classifier is the highest probability class for a given set of strings. Since the denominator of (1) is the same for all classes we take the maximum class over all classes C of the probability of each class computed in (2) to get:
In (3), we use maxC to denote the function that returns the class with the highest probability. Most Likely Class is the class in Cwith the highest probability and hence the most likely classification of the example with features F.
To train the classifier, we recorded how many programs in each class contained each unique feature. We used this information to classify a new program into an appropriate class. We first used feature extraction to determine the features contained in the program. Then we applied equation (3) to compute the most likely class for the program.
We used the Naive Bayes algorithm and computed the most likely class for byte sequences and strings.
The next data mining algorithm we describe is Multi-Naive Bayes. This algorithm was essentially a collection of Naive Bayes algorithms that voted on an overall classification for an example. Each Naive Bayes algorithm classified the examples in the test set as malicious or benign and this counted as a vote. The votes were combined by the Multi-Naive Bayes algorithm to output a final classification for all the Naive Bayes.
This method was required because even using a machine with one gigabyte of RAM, the size of the binary data was too large to fit into memory. The Naive Bayes algorithm required a table of all strings or bytes to compute its probabilities. To correct this problem we divided the problem into smaller pieces that would fit in memory and trained a Naive Bayes algorithm over each of the subproblems.
We split the data evenly into several sets by putting each ith line
in the binary into the (
![]() )th set where n is the number of
sets. For each set we trained a Naive Bayes classifier. Our
prediction for a binary is the product of the predictions of the nclassifiers. In our experiments we use 6 classifiers (n=6).
)th set where n is the number of
sets. For each set we trained a Naive Bayes classifier. Our
prediction for a binary is the product of the predictions of the nclassifiers. In our experiments we use 6 classifiers (n=6).
More formally, the Multi-Naive Bayes promotes a vote of confidence between all of the underlying Naive Bayes classifiers. Each classifier gives a probability of a class C given a set of bytes Fwhich the Multi-Naive Bayes uses to generate a probability for class C given F over all the classifiers.
We want to compute the likelihood of a class C given bytes F and the probabilities learned by each classifier Naive Bayesi. In equation (4) we computed the likelihood, LNB(C|F), of class Cgiven a set of bytes F.
The output of the multi-classifier given a set of bytes F is the class of highest probability over the classes given LNB(C|F) and PNB(C) the prior probability of a given class.
Most Likely Class is the class in C with the highest probability hence the most likely classification of the example with features F, and maxCreturns the class with the highest likelihood.