In this section we detail all of our choices of features. We statically extracted different features that represented different information contained within each binary. These features were then used by the algorithms to generate detection models.
We first examine only the subset of PE executables using LibBFD. Then we used more general methods to extract features from all types of binaries.
Our first intuition into the problem was to extract information from the binary that would dictate its behavior. The problem of predicting a program's behavior can be reduced to the halting problem and hence is undecidable [2]. Perfectly predicting a program's behavior is unattainable but estimating what a program can or cannot do is possible. For instance if a Windows executable does not call the User Interfaces Dynamically Linked Library(USER32.DLL), then we could assume that the program does not have the standard Windows user interface. This is of course an over-simplification of the problem because the author of that example could have written or linked to another user interface library, but it did provide us with some insight to an appropriate feature set.
To extract resource information from Windows executables we used GNU's Bin-Utils [5]. GNU's Bin-Utils suite of tools can analyze PE binaries within Windows. In PE, or Common Object File Format (COFF), program headers are composed of a COFF header, an Optional header, an MS-DOS stub, and a file signature. From the PE header we used libBFD, a library within Bin-Utils, to extract information in object format. Object format for a PE binary gives the file size, the names of DLLs, and the names of function calls within those DLLs and Relocation Tables. From the object format, we extracted a set of features to compose a feature vector for each binary.
To understand how resources affected a binary's behavior we performed our experiments using three types of features:
The first approach to binary profiling (shown in Figure 1) used the DLLs loaded by the binary as features. The feature vector comprised of 30 boolean values representing whether or not a binary used a DLL. Typically, not every DLL was used in all of the binaries, but a majority of the binaries called the same resource. For example, almost every binary called GDI32.DLL, which is the Windows NT Graphics Device Interface and is a core component of WinNT.
The example vector given in Figure 1 is composed of at least two unused resources: ADVAPI32.DLL, the Advanced Windows API, and WSOCK32.DLL, the Windows Sockets API. It also uses at least two resources: AVICAP32.DLL, the AVI capture API, and WINNM.DLL, the Windows Multimedia API.
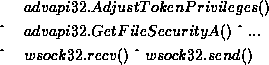
The second approach to binary profiling (seen in Figure 2) used DLLs and their function calls as features. This approach was similar to the first, but with added function call information. The feature vector was composed of 2,229 boolean values. Because some of the DLL's had the same function names it was important to record which DLL the function came from.
The example vector given in Figure 2 is composed of at least four resources. Two functions were called in ADVAPI32.DLL: AdjustTokenPrivileges() and GetFileSecurityA(), and two functions in WSOCK32.DLL: recv() and send().
The third approach to binary profiling (seen in Figure 3) counted the number of different function calls used within each DLL. The feature vector included 30 integer values. This profile gives a rough measure of how heavily a DLL is used within a specific binary. Intuitively, in the resource models we have been exploring, this is a macro-resource usage model because the number of calls to each resource is counted instead of detailing referenced functions. For example, if a program only called the recv() and send() functions of WSOCK32.DLL, then the count would be 2. It should be noted that we do not count the number of times those functions might have been called.
The example vector given in Figure 3 describes an example that calls two functions in ADVAPI32.DLL, ten functions in AVICAP32.DLL, eight functions in WINNM.DLL and two functions from WSOCK32.DLL.
All of the information about the binary was obtained from the program header. In addition, the information was obtained without executing the unknown program but by examining the static properties of the binary, using libBFD.
Since we could not analyze the entire dataset with libBFD we found another method for extracting features that works over the entire dataset. We describe that method next.
During the analysis of our libBFD method we noticed that headers in PE-format were in plain text. This meant that we could extract the same information from the PE-executables by just extracting the plain text headers. We also noticed that non-PE executables also have strings encoded in them. We theorized that we could use this information to classify the full 4,266 item data set instead of the small libBFD data set.
To extract features from the first data set of 4,266 programs we used the GNU strings program. The strings program extracts consecutive printable characters from any file. Typically there are many printable strings in binary files. Some common strings found in our dataset are illustrated in Table 1.
Through testing we found that there were similar strings in malicious executables that distinguished them from clean programs, and similar strings in benign programs that distinguished them from malicious executables. Each string in the binary was used as a feature. In the data mining step, we discuss how a frequency analysis was performed over all the byte sequences found in our data set.
The strings contained in a binary may consist of reused code fragments, author signatures, file names, system resource information, etc. This method of detecting malicious executables is already used by the anti-malicious executable community to create signatures for malicious executables.
Extracted strings from an executable are not very robust as features because they can be changed easily, so we analyzed another feature, byte sequences.
Byte sequences are the last set of features that we used over the entire 4,266 member data set. We used hexdump [18], a tool that transforms binary files into hexadecimal files. The byte sequence feature is the most informative because it represents the machine code in an executable instead of resource information like libBFD features. Secondly, analyzing the entire binary gives more information for non-PE format executables than the strings method.
After we generated the hexdumps we had features as displayed in Figure 4 where each line represents a short sequence of machine code instructions.
We again assumed that there were similar instructions in malicious executables that differentiated them from benign programs, and the class of benign programs had similar byte code that differentiated them from the malicious executables. Also like the string features, each byte sequence in a binary is used as a feature.