

Next: 5. Future Work
Up: PGMAKE: A Portable Distributed
Previous: 3. Design
Subsections
4. Evaluation
The pgmake system has been successfully implemented in SunOS 4.1.3 and
used on a network of over thirty workstations. The code additions are
highly portable and should introduce no porting problems to other
operating systems that support both PVM and GNU make.
Pgmake's main objective is to reduce the overall time to maintain
groups of targets with make. The speed improvements must justify the
extra complexity in setup and execution overhead. The following exit
criteria were deemed necessary for pgmake's acceptance as a viable tool:
- Low computational overhead in deciding to run a remote job.
- Low network overhead when shipping jobs to remote hosts.
- Low overhead in assembling status information obtained from remote hosts.
- Ability to quickly terminate remote jobs.
The following conditions are ideal for pgmake to maximize its effectiveness:
- A highly parallelizable execution hierarchy in the Makefile.
- A stable, low latency, network.
- A PVM configuration with as many reliable machines as possible.
4.0.0.3 Results.
Measurements were performed with the goal of evaluating how well our
design met these criteria.
The overhead in deciding when to run jobs remotely is negligible.
This consists of testing a boolean for each job, and a one time check
to see if the local pvmd is running. By far, the most
significant overhead of pgmake is shipping all the context
information that is required to run a job remotely.
In the test cases (building pgmake with itself), using an
arbitrarily large sized PVM, we observed a total of 10 seconds
overhead in packing, shipping, and unpacking the context information.
Note that 10 seconds is the aggregate overhead for shipping over 50
jobs to remote hosts: roughly one half second per job. In Figure
2 we see that the difference between running the entire
compilation in a single thread remotely (labeled ``1'') and locally
(labeled ``LOCAL'') is roughly 10 seconds. (The labels to the
right and left of the plots indicate the size of the PVM that was
used.)
Figure 2:
Times for a local and remote make vs. number of slots and size of PVM
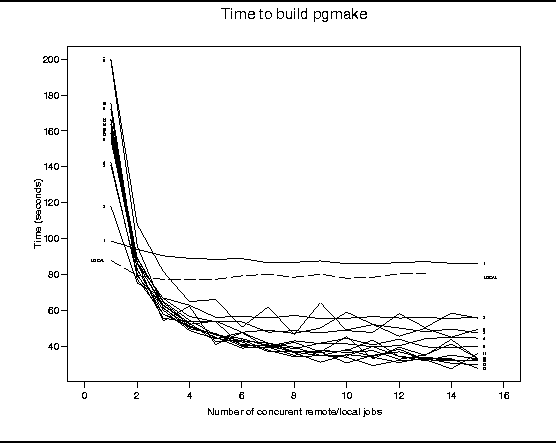 |
This overhead is offset by adding just one more machine to the PVM.
A PVM of size two or greater reduces the total compilation time by
nearly one half. Increasing the size of the
PVM to 15 nodes improves performance by 20% more.
From these results, it is almost always worth parallelizing the
compilation processes, even using relatively modest hardware.
The results obtained above and plotted in Figure
2 illustrate
two interesting phenomena with non-obvious explanations:
Both figures show an unexplained improvement in performance when the
number of concurrently running jobs is even, followed by a
deterioration in performance for an odd number of parallel jobs. This
may be a result of particular scheduling algorithms in the SunOS 4.1.3
operating system. This behavior needs to be investigated further.
When we ran our tests using a -j value of 1, the results
appeared to be random (left side of Figure 2.) There
appears to be no pattern which would explain a PVM of size 6-7
machines taking twice as much to execute a single job as opposed to a
PVM with one or two hosts.
We suspect that a combination of machine loads, PVM's scheduling and
load-balancing algorithms, and network instabilities are at work here
-- but we would not be certain before we exercise more controlled
experiments. Another theory which may explain these strange anomalies
relates to the effects of executing commands on a machine with a cold cache. When processing a source file, many resources need to be
dragged in to perform a compilation. In an test cases with one node,
the first execution of a make command with a cold cache took over
60% longer than when the cache was warm. As the number of nodes in
the virtual machine increases, and the job size remains one, the
likelihood of spawning a task on a machine with a cold cache becomes
greater. This may explain the increasing compilation times. More
experiments and measurements are needed to better understand this
phenomenon.
Given n remote processes, each of the processes still reads and
writes to the same disk partition over NFS. This becomes a problem
since most implementations of NFS are known to be lackluster in
performance, and perform synchronous write commands.
Also related to NFS, the performance of the virtual machine will
significantly deteriorate as packets pass through more routers and
gateways. It would be desirable to be able to predict what
types of degradation to expect as the conditions get worse.
4.3 Experiences
4.3.0.1 GNU Make
There is a general problem concerning the handling of standard input
when performing parallel compilation. With multiple children and one
source of standard input, only one process is allowed to have access
to standard input, while the others are given a bogus, broken pipe.
Therefore, GNU make advises users of the -j option not to
depend on using standard input at all. In pgmake, we make no attempt
whatsoever to give standard input to any process. Since no process
should expect standard input to be valid, we do not give a valid
standard input to any spawned process.
4.3.0.2 PVM
PVM has performed respectably, but can give some unexpected results.
For example, it is possible to execute the pvm_spawn() call on
a machine which is legally enrolled in PVM, but simply does not have
enough resources to perform the task. In this case, it returns a
negative return code but gives no indication which node failed.
Because of this problem, we introduced a retry loop which
attempts to respawn a failed job a specified number of times before
giving up. After introducing this loop, we found our setup to be much
more tolerant of bad nodes in the system.
Next: 5. Future Work
Up: PGMAKE: A Portable Distributed
Previous: 3. Design
Erez Zadok
1999-02-17