Our evaluation concentrated on three aspects: stability, portability, and performance. Of those, performance is the most important and is evaluated in detail.
We configured a test new server running INN version 1.7.2 and gave it a full feed from our primary news server. We turned on Usenetfs management for 6 large newsgroups and let it run. The system ran for two weeks without a single crash or indication of abnormal behavior. We then repeated the test on our production news server and got the same results. We were satisfied that the Usenetfs file system kernel module was stable.
When we started working with vnode-stackable file systems, we first searched for sources to a loopback filesystem; lofs is a good starting point for any stacking work. Linux does not have an lofs as part of the main kernel. We were able to locate a reference implementation of it elsewhere, but had to spend some time getting familiar with it and fixing bugs.2
Being familiar with kernel and file system internals, and knowing how difficult and time consuming operating system work can be, we expected the implementation to take us several weeks. However, we completed the code for Usenetfs in one day. The speed at which this was accomplished surprised us. The two contributing factors to this were the simple design we chose and Linux's easier-to-use vnode interface (especially for the readdir function.)
Given sources to an lofs for another Unix operating system, we expect to be able to port Usenetfs to the new platform within a few days to two weeks. We know it will take longer than Linux because directory reading is more cumbersome in operating systems such as Solaris and BSD-4.4. We have ported other stackable file systems to Solaris and Linux; the most complex was an encrypting file system, and it was more complicated than Usenetfs. Nonetheless, our experience has shown that once an initial stackable file system is written, it can be ported in less than 2-3 weeks to another platform.
When measuring the performance of Usenetfs we were concerned with these three aspects:
Usenetfs is a stackable file system and adds overhead to every file system
operation, even for unmanaged directories. We wanted to make this overhead
as small as possible. To test the overhead, we compared the time it took to
compile Am-utils3.
| ||||||||||||
Next, we tested specific file system actions. We set a testbed consisting of a Pentium-II 333Mhz, with 64MB of ram, and a 4GB fast SCSI disk for the news spool. The machine ran Linux 2.0.34 with our Usenetfs. We created directories with exponentially increasing numbers of files in each: 1, 2, 4, 8, and so on. The largest directory had 524288 (219) files numbered starting with 1. Each file was exactly 2048 bytes long and was filled with random bytes we read from /dev/urandom. The file size was chosen as the representative most common article size on our production news server. We created two hierarchies with increasing numbers of article in different directories: one flat and one managed by Usenetfs.
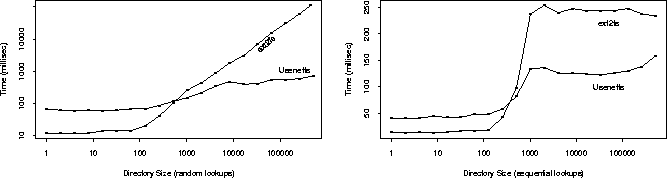
The next tests we performed were designed to match the two actions most commonly undertaken by a news server. First, a news server looks up and reads various articles, mostly in response to users reading news, and when outgoing feeds are processed. The more users there are the more random the article numbers read would be, and while users read articles in a mostly sequential order, the use of threaded newsreaders results in more random reading. The (log-log) plot of Figure 3 shows the performance of 1000 random lookups (using lstat(2)) in both regular (unmanaged) and Usenetfs-managed directories, as well as the performance of 1000 sequential lookups. The time reported is in milliseconds spent by the process and the operating system on its behalf.
For random lookups on directories with fewer than 1000-2000 articles, Usenetfs adds overhead and slows performance. This was expected because the ``bushier'' directory structure Usenetfs maintains has over 1000 subdirectories. However, as directory sizes increase, lookups on flat directories become linearly more expensive while taking an almost constant time on Usenetfs-managed directories. The difference exceeds an order of magnitude for directories with 10,000 or more articles. For sequential lookups on managed directories with about 500 or less articles, Usenetfs adds a small overhead. When the directory size exceeds 1000, lookups on regular directories take twice as long. The reason the performance flattens out for sequential lookups is because cache hits are more likely due to locality of files in disk blocks. Usenetfs performs better because its directories contain fewer files so initial lookups cost less than on unmanaged directories.
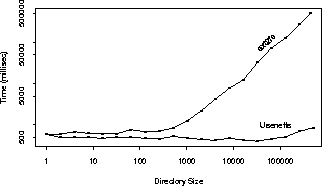
The second action a news system performs often is creating new article files and deleting expired ones. New articles are created with monotonically increasing numbers. Expired articles are likely to have the smallest numbers so we made that assumption for the purpose of testing. Figure 4 (also log-log) shows the time it took to add 1000 new articles and then remove the 1000 oldest articles for successively increasing directory sizes. The results are more striking here: Usenetfs times are almost constant throughout. Adding and deleting files in flat directories, however, took linearly increasing times. Note that in both Figures 3 (random lookups) and 4, the linear behavior of the graph for the ``regular'' (ext2fs) file system is true when the number of articles in the directory exceeds about one hundred; that is because up until that point, all directory entries were served off of a single cached directory disk block.
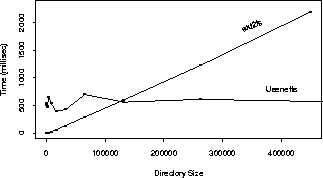
Creating over 1000 additional directories adds overhead to file system operations that need to read whole directories, especially the readdir call.4 Figure 5 shows that readdir time is linear with the size of the flat directory. Usenetfs has an almost constant overhead of half a second, regardless of directory size; that is because Usenetfs always has at least 1000 directories to read. When directories contain more than about 100,000 articles, non-Usenetfs performance becomes worse. That is because such large directories require following double-indirect pointers to data blocks of the directory, while Usenetfs directories are small enough that no indirect blocks are required.
Figures 3 and 4 showed us that
Usenetfs is beneficial for newsgroups with more than 1000 articles. Figure
5 showed us that readdir performance is better for
directories with more than 100,000 articles. It is clear from these figures
that such large directories are very well suited to be managed by Usenetfs,
and at the same time that it is not worth managing directories smaller than
1000 articles. But when directory sizes are between 1000 and 100,000 we
have to find out if the benefits of Usenetfs outweigh its overhead. Figure
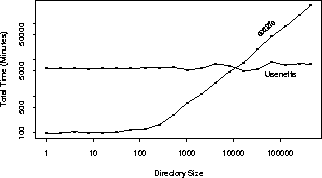
6 shows the total time possibly spent by a news system over
a period of 24 hours, taking into account Figures 3,
4, and 5 as well as the frequencies of
file system operations reported in Table 1.
It should be noted here that the numbers reported in these figures assume that the directories of these various sizes are actually managed by Usenetfs. This analysis shows that newsgroups with only 10,000 articles or more should be managed. The ``bad'' numbers with overhead reported for example in Figure 5 are valid only if those small newsgroups are managed by Usenetfs. In practice they will not be, and their overhead will be 1.2% as reported in Table 2.
The last test we ran was intended to measure how well a host performs when it is dedicated to running a news system and employs Usenetfs. Our production news server is an AMD K6/200Mhz with 16GB of fast- SCSI disks and 128MB of memory. We decided to turn on management on every newsgroup with more than 10,000 articles in it. There were 6 such newsgroups totaling about 300,000 articles, the largest of which had over 120,000 articles. That was 25% of all the articles in the spool at the time.
The news system is a complex one, composed of many programs and scripts that run at different times, and depends on external factors such as news feeds and readers. We felt that a simple yet realistic measure of the overall performance of the system would be to test how much reserve capacity is left in the server. We decided to test the reserve capacity by running a repeated set of compilations of a large package (Am-utils), timing how long it took to complete each build.
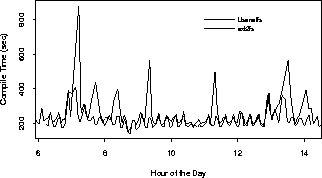
Figure 7 shows the compile times of Am-utils, once when the news server was running without Usenetfs management, and then when Usenetfs managed the top 6 newsgroups. The average compile time was reduced by 22% from 243 seconds to 200 seconds. The largest savings appeared during busy times when our server transferred outgoing articles to our upstream feeds, and especially during the 4 daily expiration periods. The largest expiration happens at 7am, when we also renumber the article ranges in the active file. Expiration of articles, and active file renumbering in particular, are affected more by the large newsgroups -- the ones with the biggest directories and the most articles to remove. During these expiration peaks, performance improved by a factor of 2-3.
There are other peaks in the server's usage (around 7:45, 8:15, 9:30, and 11:20) representing bulk article transfers to our neighbors. These actions cause the lookup and reading of many articles from the spool, a lot of which reside in large newsgroups. When Usenetfs was used, these peaks were mostly smoothed out. The overall effect of Usenetfs had been to keep the performance of the news server more flat, removing those load surges.
We believe that the performance of Usenetfs can be made better. First, we have not optimized the code yet. Secondly, our server represents a medium size news site but the hardware is powerful enough that it can handle all of the traffic it gets. If we had more traffic, kept more articles online, or our news server had used a slower CPU, we believe that Usenetfs' improvements would be more pronounced. For example, one of our neighboring news sites (sol.ctr.columbia.edu) is a busier news server. It has 543 newsgroups with over 10,000 articles each, a few of which surpass 500,000 articles. These big newsgroups account for 87% of the spool's size on that server.5 Such a busy server would benefit more from Usenetfs than our own.
Finally, we have experimented with other types of directory structures. For a given article numbered 123456, we tried to structure it using various subdirectories: 34/56/, 56/34/, and 456/. All three experiments resulted in poorer performance because they either had too many (10,000) additional directories thus imposing significantly larger overheads, or they did not cluster adjacent articles in the same directory and resulted in too many cache misses. All of the algorithms we have used are in the code base and can be turned on/off at run time. These results will be included in the final paper.