First, we used the traceroute program![[*]](foot_motif.gif) to gather
<hop-count, latency> data points measured between a host at
Columbia and several other hosts around the campus, city, region, and
continent. Latencies were measured by a Columbia host, which is a
Sun-4/75 equipped with a microsecond resolution clock. The cost of
entering the kernel and reading the clock is negligible, and so the
measurements are accurate to a small fraction of a millisecond.
to gather
<hop-count, latency> data points measured between a host at
Columbia and several other hosts around the campus, city, region, and
continent. Latencies were measured by a Columbia host, which is a
Sun-4/75 equipped with a microsecond resolution clock. The cost of
entering the kernel and reading the clock is negligible, and so the
measurements are accurate to a small fraction of a millisecond.
Next, we mounted NFS file systems that are exported Internet-wide by certain hosts. We measured the time needed to copy 1MB from these hosts using a 1KB block size. A typical result is plotted in Figure 1. Latency jumps by almost two orders of magnitude at the tenth hop, which represents the first host outside Columbia.
We chose to time the lookup operation rather than any other operation or mixture of operations for two reasons. The first is that lookup is the most frequently invoked NFS operation. We felt other calls would not generate enough data points to accurately characterize latency. The second reason is that lookup exhibits the least performance variability of the common NFS operations. Limiting variability of measured server latencies is important in our work, since we want to distinguish transient changes in server performance from long-term changes.
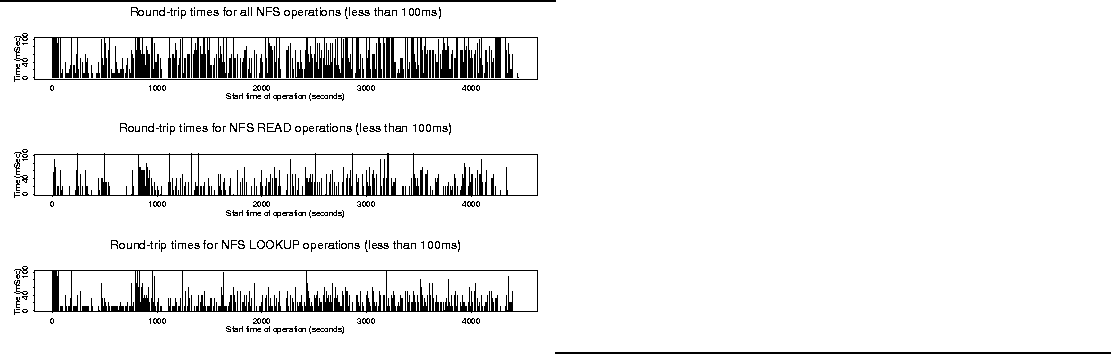
(At the outset of our work, we measured variances in the latency of the most common NFS operations and discovered huge swings, shown in Figure 2, even in an extended LAN environment that has been engineered to be uniform and not to have obvious bottlenecks. The measured standard deviations were 1027 msec for all NFS operations, 2547 msec for read, and 596 msec for lookup.)
After addition of each newly measured lookup operation, the median latency is computed over the last 30 and 300 calls. We compute medians because medians are relatively insensitive to outliers. We take a data point no more than once per second, so during busy times these sampling intervals correspond to 30 seconds and 5 minutes, respectively. This policy provides insurance against anomalies like ping-pong switching between a pair of file systems: a file system can be replaced no more frequently than every 5 minutes.
The signal to switch is when, at any moment, the short-term median latency exceeds the long-term median latency by a factor of 2. Looking for a factor of two difference between short-term and long-term medians is our attempt to detect a change in performance which is substantial and ``sudden,'' yet not transient. The length of the short-term and long-term medians as well as the ratio used to signal a switch are heuristics chosen after experimentation in our environment. All these parameters can be changed from user level through a debugging system call that we have added.
The call names the guilty file
server, the root of the file system being sought, the kernel
architecture, and any mount options affecting the file system.
Nfsmgrd uses these pieces of information to compose and broadcast an
RLP request. The file system name keys the search, while the server
name is a filter: the search must not return the same file server that
is already in use.
The RLP message is received by the nfsmgrd at other sites on the same broadcast subnet. To formulate a proper response, an nfsmgrd must have a view of mountable file systems stored at its site and also mounted file systems that it is using -- either type could be what is being searched for. Both pieces of information are trivially accessible through /etc/fstab, /etc/exports, and /etc/mtab.
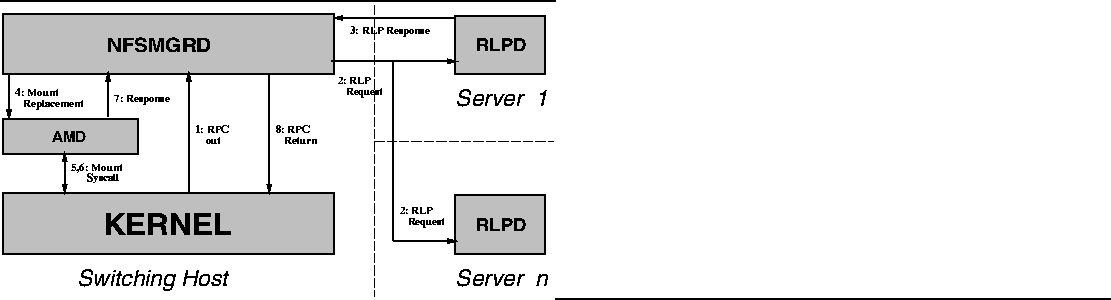
The nfsmgrd at the site that originated the search uses the first response it gets; we suppose that the speed with which a server responds to the RLP request gives a hint about its future performance. (The Sun Automounter [2] makes the same assumption about replicated file servers.) If a read-only replacement file system is available, nfsmgrd instructs Amd to mount it and terminates the out-of-kernel RPC, telling the kernel the names of the replacement server and file system. The flow of control is depicted in Figure 3.
In order to accommodate file system replacement, we have added some fields to three important kernel data structures: struct vfs, which describes mounted file systems; struct vnode, which describes open files; and struct file, which describes file descriptors.
The fields added to struct vfs, excluding debugging fields, are:
When a replacement file system is mounted, our altered version of nfs_mount() sets the replaced and replacement file systems pointing to each other.
The size of the DFT is fixed (but changeable) so that new entries inserted will automatically purge old ones. This is a simple method to maintain ``freshness'' of entries.
The DFT is a hash table whose entries contain a file pathname relative to the mount point, a pointer to the vfs structure of the replacement file system, and an extra pointer for threading the entries in insertion order. This data structure permits fast lookups keyed by pathname and quick purging of older entries.
The only field added to struct vnode is v_last_used, which contains the last time that rfscall() made a remote call on behalf of this vnode. This information is used in ``hot replacement,'' as described in Section 3.4.3.
The only field added to struct file is f_path, which contains the relative pathname from the mount point to the file for which the descriptor was opened. Different entries may have different pathnames for the same file if several hard links point to the file.
The information that bar exports a proper version of /u/foo is placed in Amd's mount-maps by system administrators who presumably ensure that the file system bar:/u/foo is a good version of whatever /u/foo should be. Therefore, we regard the information in the client's Amd mount-maps as authoritative, and consider any file system that the client might mount and place at /u/foo as a correct and complete copy of the file system. We call this file system the master copy, and use it for comparison against the replacement file systems that our mechanism locates and mounts.
The new open algorithm is shown in Figure 4. After a replacement has been mounted, whenever name resolution must be performed for any file on the replaced file system, the file system's DFT is first searched for the relative pathname. If the DFT indicates that the replacement file system has an equivalent copy of the file, then that file is used.
If the DFT contains an entry for the pathname, then the file on the replacement file system has already been compared to its counterpart on the master copy. A field in the DFT tells if the comparison was successful or not. If not, then the rest of the pathname has to be resolved on the master copy. If the comparison was successful, then the file on the replacement file system is used; in that case, name resolution continues at the root of the replacement file system.
If the DFT contains no entry for the pathname, then it is unknown whether the file on the replacement file system is equivalent to the corresponding file on the master copy.
To test equivalence, au_lookuppn() calls out of the kernel to
nfsmgrd, passing it the two host names, the name of the file
system, and the relative pathname to be compared. A partial DFT entry
is constructed, and a flag in it is turned on to indicate that there
is a comparison in progress and that no other process should initiate
the same comparison.
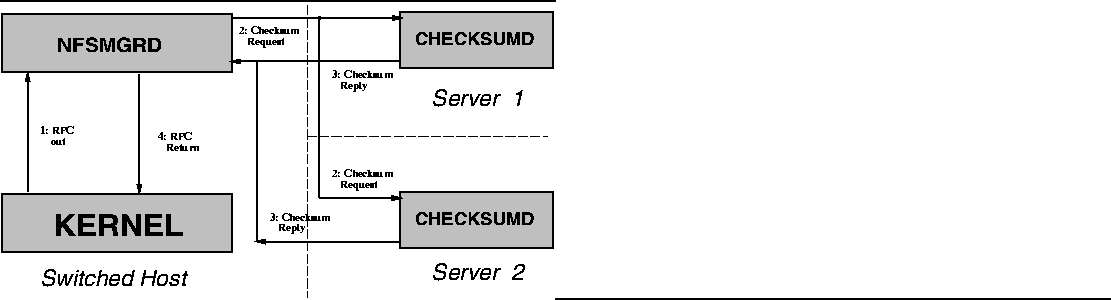
Nfsmgrd then applies, at user level, whatever tests might be appropriate to determine whether the two files are equivalent. This flow of control is depicted in Figure 5. Presently, we are performing file checksum comparison: nfsmgrd calls a checksumd daemon on each of the file servers, requesting the checksum of the file being compared. Checksumd, which we have written for this work, computes MD4 [18] file checksums on demand and then stores them for later use; checksums can also be pre-computed and stored.
Nfsmgrd collects the two checksums, compares them, and responds to the kernel, telling au_lookuppn() which pathname to use, always indicating the file on the replacement file system if possible. Au_lookuppn() completes the construction of the DFT entry, unlocks it, and marks which vfs is the proper one to use whenever the same pathname is resolved again.
In this fashion, all new pathname resolutions are re-directed to the replacement file system whenever possible.
Note that the master copy could be unmounted (e.g., Amd by default unmounts a file system after a few minutes of inactivity), and this would not affect our mechanism. The next use of a file in that file system would cause some master copy to be automounted, before any of our code is encountered.
Although this idea might at first seem preposterous, it is not, since
we restrict ourselves to read-only file systems. We assume that files
on read-only file systems change very infrequently and/or are updated with care to
guard against inconsistent reads. Whether operating
conditions uphold this assumption or not, the problem of a file being
updated while being read exists independently of our
work, and our work does not increase the danger.
We allow for a replacement file system to be itself replaced. This raises the possibility of creating a ``chain'' of replacement file systems. Switching vnodes from the old file system to its replacement limits this chain to length two (the master copy and the current replacement) in steady state.
The ``hot replacement'' code scans through the global open file table, keying on entries by vfs. Once an entry is found that uses the file system being replaced, a secondary scan locates all other entries using the same vnode. In a single entry into the kernel (i.e., ``atomically''), all file descriptors pointing to that vnode are switched, thereby avoiding complex questions of locking and reference counting.
Hot replacement requires knowing pathnames. Thanks to our changes, the vfs structure records the pathname it is mounted on and identifies the replacement file system; also, the relative pathname of the file is stored in the file table entry. This information is extracted, combined with the host names, and passed out to nfsmgrd to perform comparison, as described above. If the comparison is successful, the pathname on the replacement file system is looked up, yielding a vnode on the replacement file system. This vnode simply replaces the previous vnode in all entries in the open file table. This results in a switch the next time a process uses an open file descriptor.
Hot replacement is enabled by the statelessness of NFS and by the vfs/vnode interfaces within the kernel. Since the replaced server keeps no state about the client, and since the open file table knows only a pointer to a vnode, switching this pointer in every file table entry suffices to do hot replacement.
An interesting issue is at which time to perform the hot replacement of vnodes. Since each file requires a comparison to determine equivalence, switching vnodes of all the open files of a given file system could be a lengthy process. The four options we considered are:
We chose the ``flexible'' approach of having a daemon make a system call into the kernel which then sweeps through the open file table and replaces some of the vnodes which can be replaced. We made this choice for three reasons. First, we lacked data indicating how long a vnode lingers after its final use. Second, we suspected that such data, if obtained, would not conclusively decide the question in favor of an early or late approach. Third, the daemon solution affords much more flexibility, including the possibility of more ``intelligent'' decisions such as making the switch during an idle period.
We emphasize that the system call into the kernel switches ``some'' of the vnodes, since it may be preferable to bound the delay imposed on the system by one of these calls. Two such bounding policies that we have investigated are, first, switching only N vnodes per call, and, second, switching only vnodes that have been accessed in the past M time units. Assuming that file access is bursty (a contention supported by statistics [14]), the latter policy reduces the amount of time wasted switching vnodes that will never be used again. We are currently using this policy of switching only recently used vnodes; this policy makes use of the v_last_used field that we added to the vnode structure.
The NFS security model is the simple uid/gid borrowed from UNIX, and is appropriate only in a ``workgroup'' situation where there is a central administrative authority. Transporting a portable computer from one NFS user ID domain to another presents a security threat, since processes assigned user ID X in one domain can access exported files owned by user ID X in the second domain.
Accordingly, we have altered rfscall() so that every call to a replacement file system has its user ID and group ID both mapped to ``nobody'' (i.e., value -2). Therefore, only world-readable files on replacement file systems can be accessed.
The nfsmgr_ctl system call allows query and control over almost all data structures and parameters of the added facility. We chose a system call over a kmem program for security. This facility was used heavily during debugging; however, it is meant also for system administrators and other interested users who would like to change these ``magic'' variables to values more suitable for their circumstances.