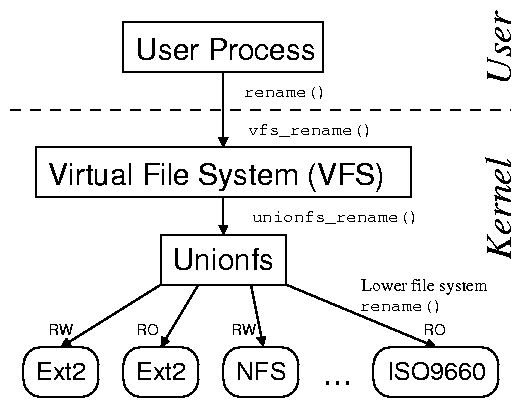
| Feature | Plan 9 | 3DFS | TFS | 4.4BSD | Unionfs |
| 1 | Unix semantics: Recursive unification | | Yes | Yes | Yes | Yes |
| 2 | Unix semantics: Duplicate elimination level | | User Library | User NFS Server | C Library | Kernel |
| 3 | Unix semantics: Deleting objects | | | Yes | Yes | Yes |
| 4 | Unix semantics: Permission preservation on copyup | | | | | Yesa |
| 5 | Multiple writable branches | Yes | | | | Yes |
| 6 | Dynamic insertion & removal of any branch | | | | | Yes |
| 7 | Dynamic insertion & removal of the top branch | Yes | Yes | | Yes | Yes |
| 8 | No file system type restrictions | Yes | Yes | Yes | b | Yes |
| 9 | Creating shadow directories | | Yesc | Yes | Yes | Yesc |
| 10 | Copyup-on-write | | Yes | Yes | Yes | Yesd |
| 11 | Whiteout support | | Yese | Yes | Yes | Yes |
| 12 | Snapshot support | | | | | Yes |
| 13 | Sandbox support | | | | | Yes |
| 14 | Implementation technique | VFS | User | User NFS Server | Kernel FS | Kernel FS |
| | (stack) | Library | + Kernel helper | (stack) | (fan-out) |
| 15 | Operating systems supported | Plan 9 | Manyf | SunOS 4.1 | 4.4BSD | Linuxg |
| 16 | Total LoC | 6,247h | 16,078 | 16,613 | 3,997 | 9,784 |
| 17 | Customized functionality | | | | | Yes |