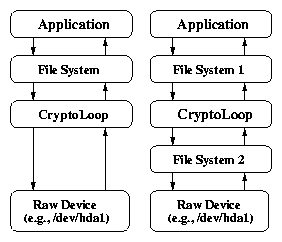
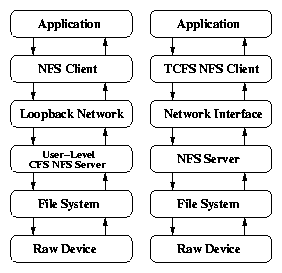
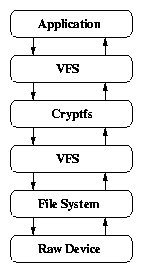
| Feature | LOOPDEV | LOOPDD | EFS | CFS | NCryptfs | |
| 1 | Category | Block Based | Block Based | Disk FS | NFS | Stackable FS |
| 2 | Location | Kernel | Kernel | Hybrid | User Space | Kernel |
| 3 | Buffering | Single | Double | Single | Double | Double |
| 4 | Encryption unit | 512B | 512B | 512B | 8B | 4KB/16KB |
| 5 | Encryption mode | CBC | CBC | CBC (?) | OFB+ECB | CTS/CFB |
| 6 | Write Mode | Sync,Async | Async Only | Sync,Async | Async Only | Async only, Write-Through |
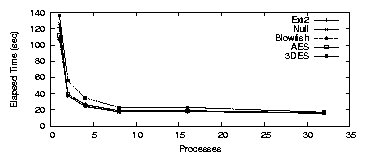
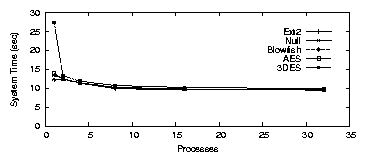
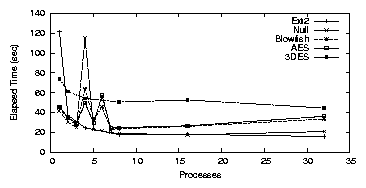
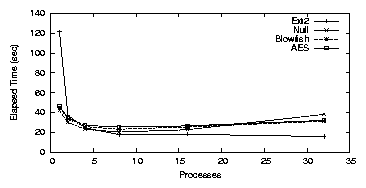
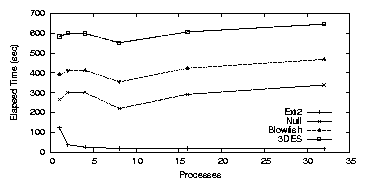
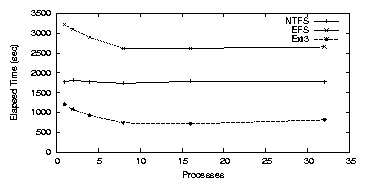
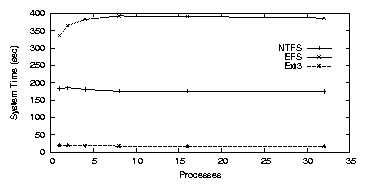
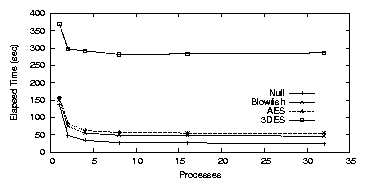
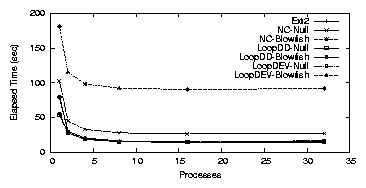
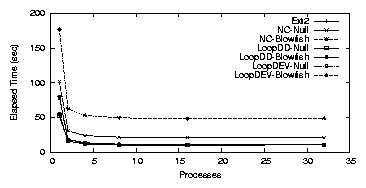
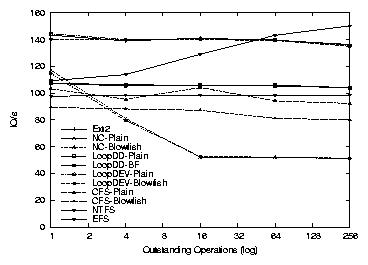
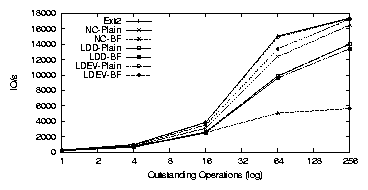

| Cipher | Key Size (bits) | Speed MB/s |
| AES | 128 | 27.5 |
| AES | 192 | 24.4 |
| AES | 256 | 22.0 |
| Blowfish | Any | 52.6 |
| 3DES | 168 | 10.4 |
| Null | None | 694.7 |