| <Trace File> | → | <Trace Header> <Trace Data> |
| <Trace Header> | → | Magic Version uname_info {<Message Descriptor> } {<Argument Descriptor> } |
| <Message Descriptor> | → | msg_id message_description |
| <Argument Descriptor> | → | arg_id message_description |
| <Trace Data> | → | <Start Message> {<Message> } <Stop Message> |
| <Start Message> | → | MSG_START length {<Argument> } |
| <Stop Message> | → | MSG_STOP length {<Argument> } |
| <Message> | → | msg_id length {<Argument> } |
| <Argument> | → | arg_id length value | arg_id value |
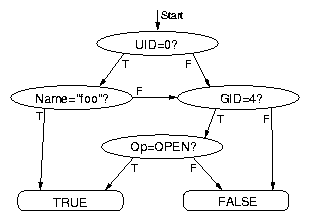
{
{ cuid = 0 OR cgid = 1 }
{ stream = { STR_POST_OP | STR_PID | STR_UID | STR_TIMESTAMP } }
{ compress; filename = "/mnt/trace.log" buf = 262144 }
}
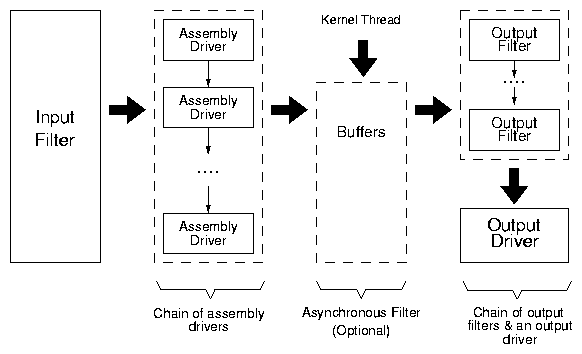
The configuration file contains three sections for each tracer: input
filter, assembly drivers, and output filters and driver. In this
example, the input filter contains two OR-ed predicates. It uses the
stream assembly driver, with the parenthesized parameters specifying
the verbosity settings. Finally, the output chain consists of the
compression filter and the file output driver
that specifies the name of the trace file and the buffer size being
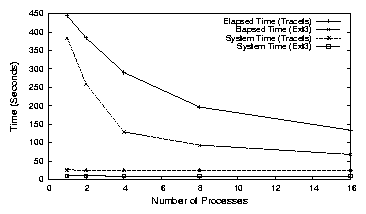
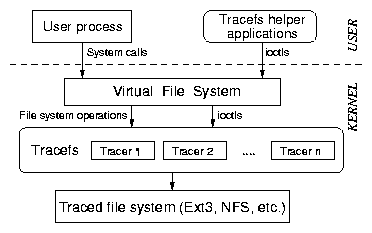
used. This configuration file is parsed by a tool that calls ioctls
to specify the tracer. For the input filter, the tool first
constructs a DAG which is then passed to the kernel in a
topologically-sorted array. The kernel reconstructs the DAG from this
array. If the trace parameters are correct, the kernel returns a
unique identifier for the tracer. This identifier can be used later to
start and stop tracing using ioctls.
The input filter determines which operations will be traced and under
what conditions.
The ability to limit traces provides
flexibility in applying Tracefs for a large variety of applications.
We now discuss three such applications: trace studies, IDSs, and
debugging.
Trace Studies When configuring Tracefs for collecting
traces for studies, typically all operations will be traced using
a simple or null input filter. The stream
assembly driver will trace all arguments.
The output
driver will typically be a file with buffered asynchronous writes for
maximum performance.
For trace studies that involve analysis of the distribution of file-system
operations and their timing, the aggregate assembly driver can be used in
conjunction with a simple or null input filter. The aggregate driver
provides detailed information about operations with minimal overhead.
For example, using the aggregate driver, it is easy to determine which
operations take the longest time, and to locate anomalous behavior,
such as a small fraction of write operations taking
an abnormally large time to complete. We have used Tracefs to
analyze the performance of other file systems during their
development.
Intrusion Detection Systems An IDS is configured with two
tracers. The first tracer is an aggregate counter that keeps track of
how often each operation is executed. This information is periodically
updated and a monitoring application can raise an alarm in case of
abnormal behavior. The second tracer creates a detailed operation
log. In case of an alarm, the IDS can read this log and get detailed
information of file system activity. An IDS needs to trace only a few
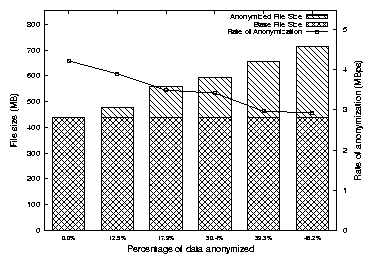
operations. The output filter includes checksumming and encryption for
security. The trace output is sent over a socket to a remote
destination, or written to a non-erasable tape. Additionally,
compression may be used to limit network traffic.
To defeat denial of service attacks, a QoS output filter can be
implemented. Such a filter can effectively throttle file system
operations, thus limiting resource usage.
Debugging For debugging file systems, Tracefs can be used with
a precise input filter, which defines only the operations that are
a part of a sequence of operations known to be buggy. Additionally,
specific fields of file system objects can be traced, (e.g., the
inode number, link count, dentry name, etc.). No output filters need to
be used because security and storage space are not the primary concern and the
trace file should be easy to parse. The file output driver is used in
unbuffered synchronous mode to keep the trace output as up-to-date as
possible.
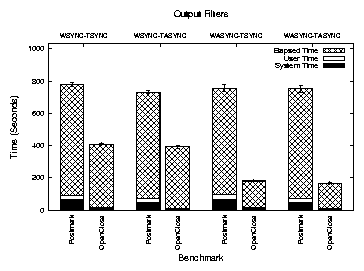
| Synchronous File System | Asynchronous Filter | |
| WSYNC-TSYNC | yes | no |
| WSYNC-TASYNC | yes | yes |
| WASYNC-TSYNC | no | no |
| WASYNC-TASYNC | no | yes |