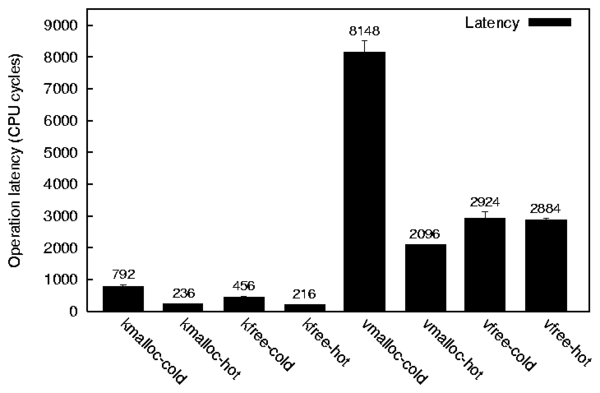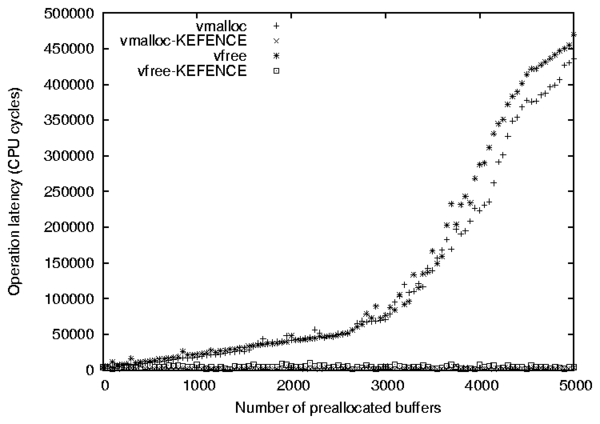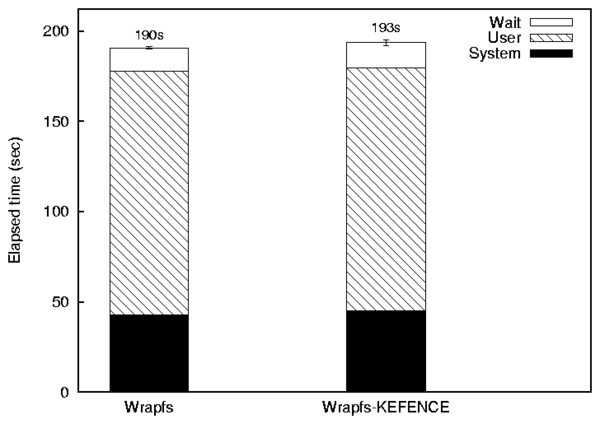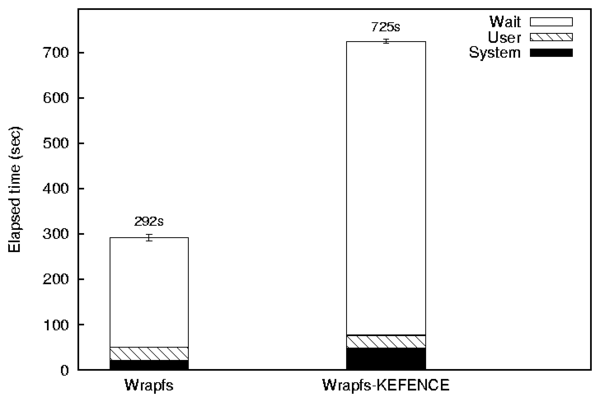
| vmalloc | kmalloc | |
| Total calls in the kernel code | 505 | 4,469 |
| Total calls in file system code | 63 | 748 |
| Invoked during boot up | 68 | 134,223 |
| Buffers still in memory after boot | 7 | 3,827 |
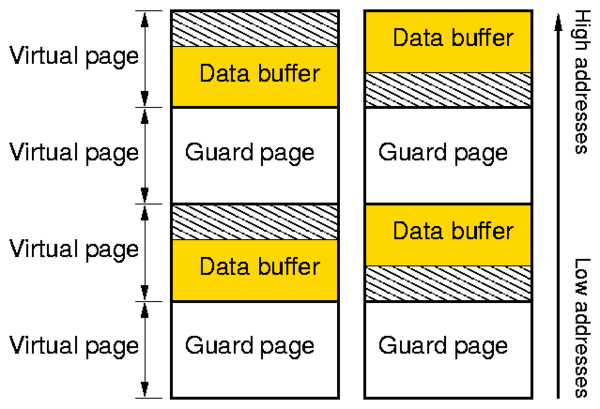
Buffer OVERFLOW detected! Buffer allocated in module: wrapfs file: dentry.c function: wrapfs_alloc_dentry line: 97
| File | Lines added | Added functionality |
| or changed | ||
| arch/i386/mm/fault.c | 6 | page fault handler hook |
| include/linux/gfp.h | 1 | upper or lower page edge alignment flag |
| include/linux/vmalloc.h | 51 | macros and vm_struct members to store extra information about the buffer |
| init/Kconfig | 27 | new kernel configuration options |
| mm/vmalloc.c | 281 | virtual memory areas cache and hash table, page fault report generation |
| Total: | 366 |
|