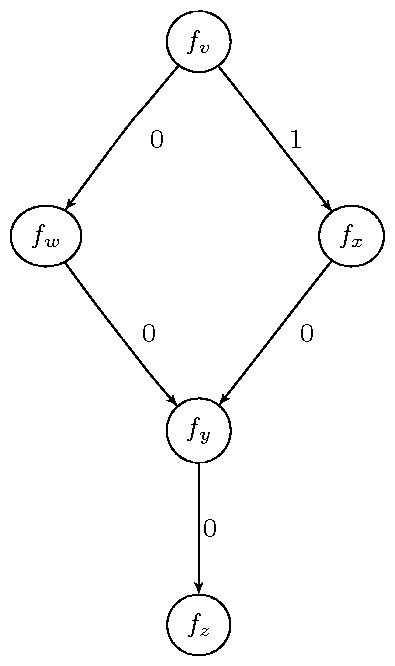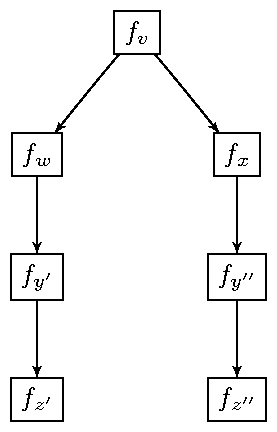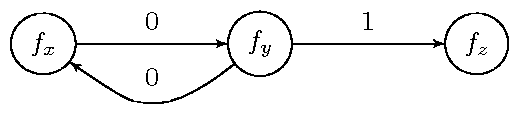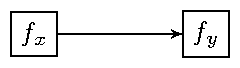
f0 {
time1 = GET_CYCLES();
...
f0,0();
...
f0,i();
...
f0,n();
...
time2 = GET_CYCLES();
latency = time2 - time1;
record_latency_in_histogram(latency);
}
|
f0 {
root->start = GET_CYCLES();
...
f0,0();
...
c = root->child[i];
c->start = GET_CYCLES();
f0,i();
c->latency = GET_CYCLES() - c->start;
if (c->latency > c->maxlatency)
c->maxlatency = c->latency;
...
f0,n();
...
root->latency = GET_CYCLES() - root->start;
if (is_in_peak_range(root->latency)) {
process_latencies();
num_calls++;
}
if (num_calls % decision_calls == 0) {
choose_root_causes();
num_calls = 0;
}
reset_latencies();
}
|
f0,i {
...
c = parent->child[j];
c->start = GET_CYCLES();
f0,i,j();
c->latency = GET_CYCLES() - c->start;
if (c->latency > c->maxlatency)
c->maxlatency = c->latency;
...
}
|